Nothing works without review

So far in the Summer Challenge, we've discussed the habit of ubiquitous capture, the process of clarifying what you capture, how to use contexts to divide and conquer task lists, the differences between tasks and projects, and a painfully detailed look at my productivity setup. If you've been following along with this and practicing these habits yourself, you're doing yourself a major favor in preparing for the upcoming academic year.
There's one final item that we've mentioned but not detailed, and it's the most important part: the review process. The collection of lists, habits, and so on that we've detailed isn't really a system without review. Review is what ties all of the pieces together and makes it feel like a connected process rather than an unmanageable number of small processes.
So what is review, and how does it work?
What is review?
The review process refers to actions you take to make sure all the parts of your system are complete, current, and connected. Following a review, there should be
- Nothing in your inboxes;
- Nothing from your inboxes that hasn't been clarified and given a home;
- Nothing on your lists that is no longer relevant; and
- No surprises.
In other words, you do a review on a regular basis to make sure there's nothing in your world that is quietly draining you of energy in the background, like a leaky faucet, via the Zeigarnik Effect. You do a review because although you may think you're saving time and energy by not reviewing, in reality what you're doing is just choosing to overlook the leaks. Opting out of regular reviews is a fast track to a repeat of the exhaustion so many felt during and after AY 2020-2021.
Review is not just a single thing, but a series of nested routines that take place at different scales. Here, I want to describe three that I use: Daily Review, Morning Startup, and the all-important Weekly Review.
Daily Review
The following routine is something I do at the end of each workday. In fact the routine is my way of willing the end of the day to happen, and it defines what it looks like.
- Go through all inboxes and get them to zero, using the Clarify loop. My list of inboxes includes my physical inbox, three email accounts, the
_INBOXfolder in Google Drive, the top layer of notes in Google Keep, the Inbox list in my Next Actions Trello board, and bulleted items captured during the day in my bullet journal. Each item needs to end up in an appropriate home somewhere. - Look at the calendar for tomorrow and the rest of the week just to have a heads-up about anything upcoming. If scanning the calendar triggers a reminder, capture it and clarify it on the spot.
- Update the Next Actions list by marking off anything that was completed or which is no longer relevant.
- Loop through the Projects list and make sure all active projects have a next action that is also present on the Next Actions list. If a project no longer has a next action, move it to a "Projects On Hold" list.
- Clean up the physical workspace. Remove clutter and trash. If there's a physical item I'm not sure what to do with, it goes in a physical inbox for Clarification later (or right then, if it's easy).
- Write the day's Work Journal. In my bullet journal, I list three Wins for the day, three Challenges, and three Lessons I learned. During the worst moments of 2020 I wrote down three things I am grateful for. It helps me reflect on what happened and what I learned, and it's significant to revisit these entries once some time has passed.
- End by drawing a line under the work journal, and actually say "SHUTDOWN COMPLETE". Sure, this is cheesy and gets me some weird looks when I do this in public. But I still do it.
This process typically takes me under 30 minutes. Although I have this blocked out on my calendar each workday, it doesn't always happen. For example I might have a meeting scheduled up to 5pm, and then the meeting goes over time, and then I have to switch immediately to Dad mode to make dinner, and by the time I have time to think about it, it's 7pm and I'd just rather not.
But I think it's important to do a Daily Review for at least two reasons. First, it makes the Weekly Review much easier. Second, it actually ends the workday. Many academics are unaware they can just stop working if they wanted to. They grade and send emails well into the evening and weekends, getting worse at both by the minute and making themselves and everyone else miserable. The Daily Review is a way of ritualizing the act of being done with work for the day and this has a powerful, subversive effect.
You may say But then I'll get behind and never get caught up! Question: Did staying up all night and into the weekend get you caught up? No? Then why not just admit it, and get some sleep and spend time with your family instead?
The Morning Startup
This mini-review is something I do either first thing in the morning or just before bed at night. It's not really necessary but I find it helpful. This takes me 5 minutes at most.
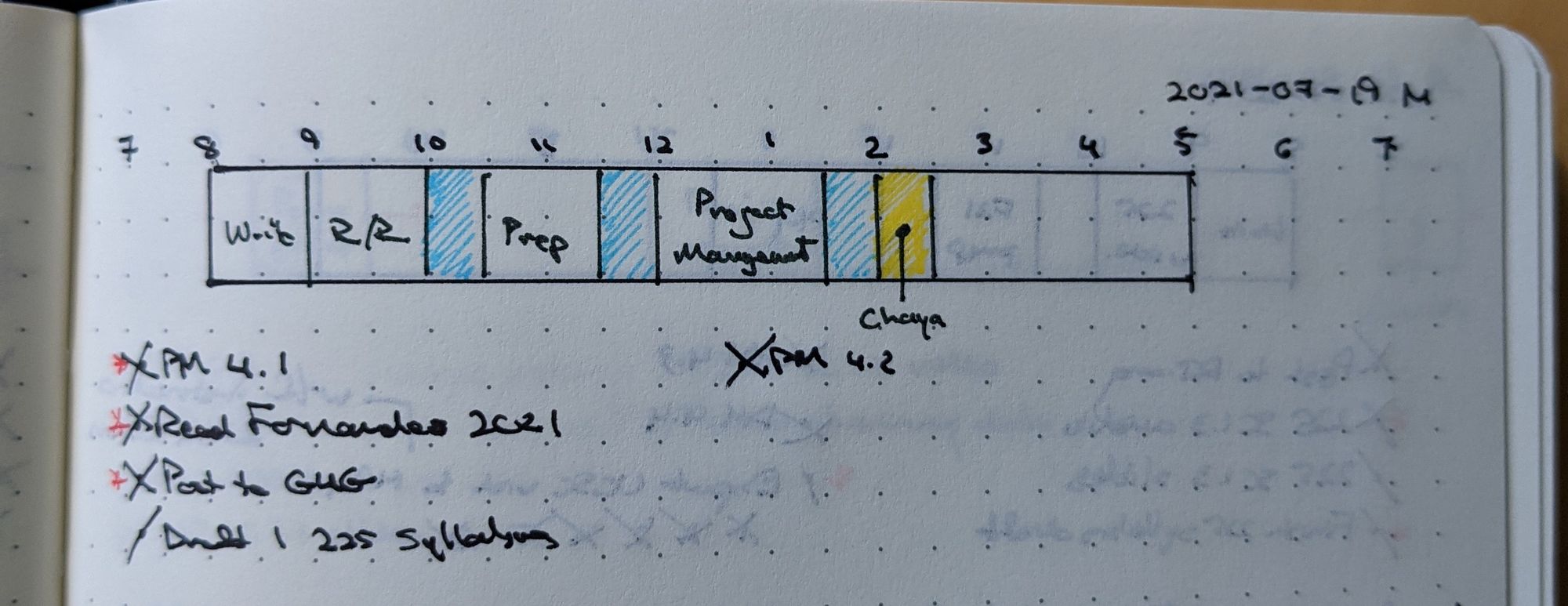
First I make a visual timeline for the day, from 7am to 7pm. Block off the times between 8am and 5pm (or whatever your "working hours" are) and then add in blocks of time dedicated to specific projects or tasks. Color code if you feel like it. Below the timeline, list priority tasks for the day — either things that must get done because they have an external deadline, or things that I want to get done and am committing to focus on that day.
Put limits on the length of this list. My limit is eight. If I have more than eight priority items, none of them is really a priority. Of these, mark up to three of them as Most Important Things (MIT's) – the things that, if all else goes sideways, really and truly need to get done that day.
Weekly Review
The Daily Review and Morning Startup are like the daily hygienic habits that all grownups should be doing, like showering or brushing your teeth. We should be doing these daily, but let's be real — we all skip these from time to time for various reasons, and although it's gross, occasional misses on these don't have long-term effects (other than maybe your personal life). The Weekly Review, on the other hand, is more than just hygiene — it really must be done regularly or none of the effort from installing the other habits will work.
Many articles have been written about the weekly review — here's a semi-official one from David Allen Co. and here's one I wrote in 2017. I've been tweaking and updating my weekly reviews ever since switching to a bullet journal inflected system because it turns out that introducing an analog focus really changed the process I was using. So here's my updated-for-2021 weekly review process.
"Step 0" is to set aside dedicated time and space for this. My usual is to take 90 minutes, every Sunday morning while the kids are still sleeping, in my home office. It's the only work-related thing I allow myself to do on Sundays.
Get Clear
- Declutter and wipe down the workspace. Remove all items (except my computer monitor) from the desk and wipe it down with disinfectant wipes; shut down all electronic devices and wipe those down; wipe down all the other physical spaces I come into contact with. I started doing this "weekly wipedown" at the onset of the pandemic, and liked it, so I kept it up. (I have four cats and they like to hang out in the office, so weekly wipedowns are still very relevant.)
- Collect all loose physical items in the workspace. This is the Capture process for physical items sitting around. Once I've removed physical stuff to do the wipedown, it's easy to notice things that were just sitting there that need a better home. Once they are in the physical inbox and stuff has been wiped down, put the desk back together, now clean and free of clutter.
- Process all inboxes to zero. This shouldn't take a ton of time if you've been disciplined about Daily Review. The point is that by the end of this step, everything that had our attention has been processed and given a home (possibly the trash).
- Run through a mind sweep. Documents like this one give a series of triggers for things we may not have been thinking about that need to be thought about. As you go through the sweep, it will likely surface stuff that needs to be addressed. Put it in an inbox and proceed onward.
- Review foundational documents. Before I move on to the next phase of this review, I've found it helpful to go over my big picture by reminding myself of yearly goals and priorities, my core values, and so on.
It usually takes me about 15-20 minutes to complete this part. Don't overthink it. Those with massively overstuffed inboxes can't complete this in that amount of time, I get it. It really depends on having good email hygiene on a daily basis. You might have to settle for only processing the emails from the last 3 days at first.
Get Current
- Review Next Actions lists. Mark off any items that have been completed or are no longer relevant, and review any remaining ones for reminders.
- Review the calendar. Look at the calendar two weeks into the past, at the current week, and then 2-4 weeks into the future. If doing so triggers any reminders of stuff to do, capture those and put them in an inbox. This is the part of the Weekly Review that often takes the most time, especially during the school year when examining the calendar triggers all the course prep and grading tasks I need to do.
- Review the Waiting For list. This list contains anything significant that someone else is doing for me — delegated items, replies to important emails I've sent, payments for speaking gigs, etc. If any of these has been resolved, mark them off. If any need following up, turn it into an action and capture it into an inbox (e.g. "Follow up with Alice about the meeting agenda").
- Review the Future list. This is for items that are Next Actions that can't be started until later. For example, I need to set up the LMS for my Fall courses but I can't do that until August. Until August 1, I can do nothing about this, so I want it out of sight/out of mind – hence the Future list, specifically a sub-list for August. If there are any items that can now be done, for example the first of the month has arrived, move those to Next Actions, or to another month, to Someday/Maybe, to the trash or somewhere else depending on what's appropriate.
- Review the Projects lists. Check in on each project and make sure that you're clear on the status and goals of each one. Update the actions list for each project and make sure each active project has a Next Action which is duplicated on the Next Actions list. If there is no next action, the project is either complete (delete it, or archive it in a "Done" list) or it's on hold (move it to a "Projects on hold" list or possibly the Waiting For list).
- Review 120-day goals. I set these near-term goals in the form of OKRs whenever I do a Trimesterly Review. For each one, ask: What progress have I made? What successes have I had in moving toward my goals? Where have I experienced resistance and what's blocking me? What do I need to change or continue doing in the next week to move forward? These questions usually trigger other things to do during the week, and they help me get a sense of my overarching priorities for the week.
- Clarify all items that got put in the inbox from previous steps and process them. All these "Get Current" steps tend to generate more stuff for you. That's the sign of a productive mind. Do one more round of Clarification so that this stuff has a home. Some of that stuff will end up as to-do items, but not all of it! Some of it will be Someday/Maybe material; some will end up on the Future list; some will be delegated; some you'll just end up saying "Never mind" to and then trashing it. For those that do end up as Next Actions, in my system — which uses Trello to manage next actions — at this point I label them Week or Month (if it's something to be done this week or this month), Weekly Priority (if it's a super-important thing that demands focus this week), or a special red label called DO SOMETHING which I reserve for tasks that are urgent or have been sitting around forever stuck in neutral. For tasks that were labeled Week but did not get done last week, I have a Custom Field for "Migrations" which shows the number of times the item has been punted from one week to the next; when that number reaches 3 — i.e. it's been in the system for a month as a task labeled for this week — I have an automated rule in Trello that adds the red DO SOMETHING label to it. My personal rule is that if an item has been migrated three weeks, it's time to put up or shut up about it — either complete it, delete it, or move it to Future or Someday/Maybe, but stop pretending it's important. Once all the items are tagged, move them to the appropriate context list.
- Move over to the bullet journal and set up a weekly spread. The canonical bullet journal setup has a nested sequence of "logs" — future log, monthly log, weekly log, etc. I've found those cumbersome, so I use Google Calendar as my future log, and the Trello labels above take the place of the monthly and weekly log. However, I do find it very helpful to have a weekly dashboard for priorities and tasks. So I set aside a single new page in the notebook for the new week. Then make a short list of top priorities, in general terms, for the week. Then I make a list of "roles and goals" for the week — specific goals pertaining to each of my life roles as a teacher, learner, writer, leader, family guy, and person with an active lifestyle. And then I hand-copy all of the tasks labeled Week from Trello to the notebook. This hand-copying is boring, tedious, and physically uncomfortable. Therefore it forces me to keep a lid on the number of tasks I designate as "to be done this week".
- Finally (whew!) create time blocks for the week on your calendar for priority items. Time blocking or "time boxing" is where you schedule time in your calendar for focused work on things. We already do this for appointments and classes; this is where you exert some control over your schedule and do the same for other priorities. Look back at the priority items for the week and box off time so that you'll have sufficient dedicated time to complete them.
Get Creative
This ending portion is to help you remember that you are not a machine but a human being with aspirations and capital to invest.
- Review the Someday/Maybe list. If there's something you put on there that you now feel like you want to promote to a project or a real Next Action, do it. If there's something on there that's no longer a thing you want to do, delete it. If something triggers another Someday/Maybe, add it. This is where your dreams go.
- Brainstorm any big, risky, or creative ideas you may have for improving yourself or investing your personal capital. Write a book about flipped learning. Take the family on a vacation outside my country. Learn to play the mandolin. I like to keep a list of these ideas inside Someday/Maybe.
This portion is usually quick, maybe 10 minutes at most, although if I hit upon an interesting creative/risky idea I may opt to spend some more time with it.
And on that note — you're done.
There are other levels of review I haven't detailed here, especially the Trimesterly Review, and some people like to do a monthly review (although I don't). These are important but, in my view, not as much as these smaller and more frequent reviews.
If all this sounds like a lot of work, you're not wrong. I probably spend 4-5 hours a week in a combination of these reviews. But I don't have the time to spend on that you may say. But I tell you, I've tried going without these reviews before — I'm too busy, too tired, etc. etc. etc. — and every time I end up spending more time and energy frantically trying to salvage all my mismanaged tasks and projects than the 4-5 hours it would have taken to manage them properly in the first place. Put it this way: You are going to spend at least 4-5 hours this week thinking about your tasks or projects. Do you want to do this in an orderly, controlled environment where you are in the driver's seat? Or do you want to do this chaotically Whack-a-Mole style where you have zero control and don't even know what you don't know? Which approach leads to less exhaustion and burnout?
I've learned it's just better for everyone if I simply shut up, sit down, and do this every week. And like a lot of disciplines that look forbidding on the outside, it actually feels good once you stop complaining about it. This weekly review time — on a quiet Sunday morning, with coffee and a good Spotify playlist going — is a time I look forward to each week where I come out feeling energized, centered, and ready to actually do work.